한컴, PDF 추출 핵심 기술 글로벌 오픈소스로 공개
등록 2025.09.17 17:20:47
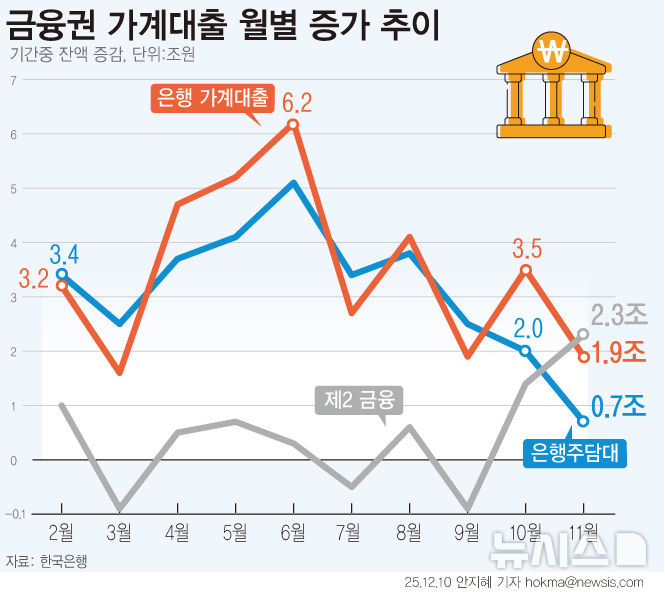
AI 학습 가로막던 PDF '데이터 감옥' 해방글로벌 AI 생태계와 직접 연동
경쟁 오픈소스 대비, 벤치마크 지표에서 85% 수준의 성능 입증

한글과컴퓨터 CI(사진=한글과컴퓨터 제공) *재판매 및 DB 금지
[서울=뉴시스]송혜리 기자 = 한글과컴퓨터는 인공지능(AI) 학습과 활용 과정에서 고질적인 난제로 지적돼 온 PDF 문서 데이터 처리 병목 현상을 해소할 핵심 기술을 글로벌 오픈소스로 공개했다고 17일 밝혔다.
이번에 공개한 '오픈데이터로더 PDF'는 한컴이 오랜 기간 축적한 문서 처리 기술력을 바탕으로 개발한 PDF 데이터 추출 엔진이다. 한컴은 지난 7월 PDF 기술 전문 기업 듀얼랩과 업무협약(MOU)을 체결하고 오픈소스 기반 PDF 데이터로더를 공동 개발해왔다.
오픈데이터로더 PDF는 PDF 문서 내 텍스트, 표, 이미지, 레이아웃 정보를 추출해, AI 학습에 즉시 활용할 수 있는 정형화된 데이터(JSON, Markdown, HTML)로 변환한다. 특히 공식 홈페이지에 공개된 벤치마크 테스트 결과 사람의 읽기 순서를 측정하는 지표인 NID(Normalized Indel Distance)에서 타 기술 대비 85%라는 높은 수치를 기록하는 등 다양한 테스트에서 탁월한 성능을 보여줬다고 회사 측은 강조했다.
한컴은 이번 오픈소스 공개를 단순한 기술 공유에 그치지 않고, AI 생태계 전반의 오픈소스 확산과 기술 고도화를 추진하고 있다. 이를 위해 챗GPT, 제미나이, 랭체인 등 주요 AI 프레임워크와의 연동·호환성을 강화하고, 깃허브를 통한 글로벌 개발자 커뮤니티와의 협력을 이어갈 계획이다.
정지환 한컴 최고기술책임자(CTO)는 "AI 전환(AX) 시대, 오픈소스는 더 이상 선택이 아닌 기업과 사회 전반의 혁신과 경쟁력 확보를 위한 필수 전략"이라며 "이번 오픈데이터로더 PDF 핵심 기술 공개를 통해 전 세계 개발자들에게 인정받고 협력을 통해 PDF 데이터 추출 기술을 한 단계 더 발전시켜 글로벌 최고 수준의 AI 데이터 추출 기술을 완성하겠다"고 말했다. 이어 "연말에는 AI 기반 문서 인식 기술을 추가하는 등 오픈소스 프로젝트를 지속적으로 고도화하겠다"고 덧붙였다.
◎공감언론 뉴시스 [email protected]
Copyright © NEWSIS.COM, 무단 전재 및 재배포 금지