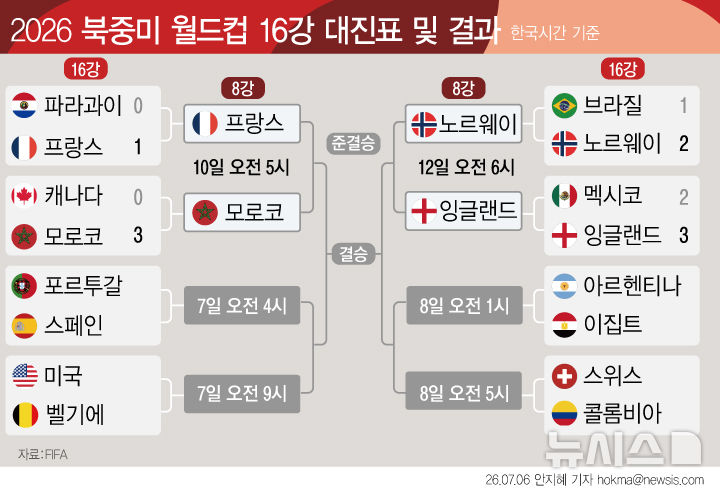
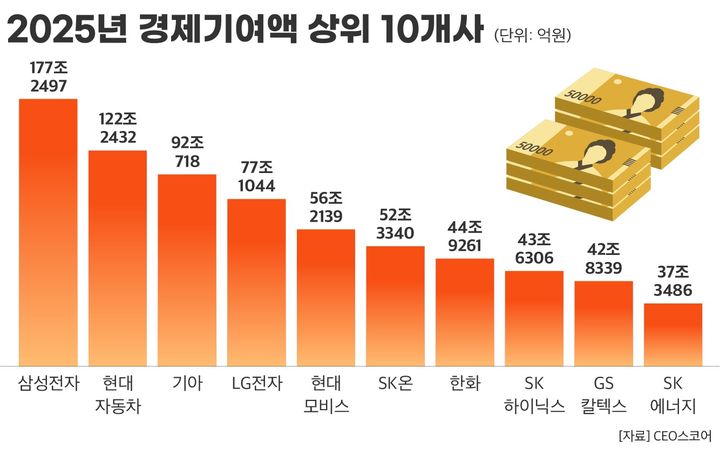
휴먼랩스, 글로벌 사우스 언어 전반에 걸친 AI 음성 벤치마킹 보고서 출시
등록 2026.05.14 17:35:00수정 2026.05.14 18:51:10
최대 독립 벤치마킹 보고서인 브릿지, 7개 지표 점수 스택을 사용해 22개 비영어 언어에서 15개 상용 모델 평가
벵갈루루, 인도, 2026년 5월 14일 /PRNewswire/ -- 물리적 및 음성 AI 데이터 인프라 기업 휴먼랩스(Humyn Labs)가 5월 13일, 글로벌 사우스(Global South) 전반의 비영어권 언어에서 실제 대화 데이터를 기반으로 한 상용 AI 음성 인식 도구를 위한 최대 독립 벤치마크인 브릿지(Benchmark of Regional & International Data for Global Evaluation, BRIDGE)를 발표했다. 라틴 아메리카 스페인어 방언, 브라질 포르투갈어, 베트남어 등 22개 언어에서 15개 모델을 테스트하는 이 벤치마크는 55억 명 이상이 사용하는 언어를 평가한다. 전체 보고서는 여기에서 확인할 수 있다.
 and Co-Founder Manish Agarwal (R), Humyn Labs")
Co-Founder Ishank Gupta (L) and Co-Founder Manish Agarwal (R), Humyn Labs
연구 결과에 따르면 글로벌 순위는 지역 성능의 신뢰할 수 있는 지표가 아닌 것으로 나타났다. 일레븐랩스 스크라이브 v2(ElevenLabs Scribe v2)가 10.6%의 단어 오류율로 전체 1위를 차지했지만, 베트남어에서는 어셈블리AI 유니버설(AssemblyAI Universal)이 글로벌 순위 12위임에도 불구하고 가장 좋은 성과를 내며 3위를 기록했다. 보고서는 또한 베네수엘라 스페인어, 브라질 포르투갈어, 지역 간 화자 쌍에서 주요 성능 격차를 발견했다.
휴먼랩스의 마니시 아가르왈(Manish Agarwal) 공동 창업자는 "모델들이 자신의 작업을 스스로 채점하고 있다. ASR 제공업체들은 독립적인 검증이 거의 없이 영어를 우선으로 하고 인터넷으로 학습된 데이터 세트로 구축된 벤치마크를 사용하여 자체 정확도 점수를 발표했다. 한편 기업들은 글로벌 사우스의 사용자들이 실제로 말하는 방식을 거의 반영하지 못하는 수치를 기반으로 수백만 달러의 배포 결정을 내리고 있다. 브릿지 이전에는 비영어 시장 전반의 실제 대화 오디오에 대한 독립적인 벤치마크가 없었다"고 말했다.
브릿지는 표준 단어 및 문자 오류율 외에 의미 유사성(Semantic Similarity), 코드 스위치 F1(Code-Switch F1), 외래어 단어 오류율(Loan Word WER), 음소 기반 오류율(Phoneme-Informed Error Rate), 단어 정보 손실(Word Information Lost)을 포함한 7개의 지표를 적용한다. 이 벤치마크는 베트남어에서 높은 단어 오류율을 가진 모델들이 여전히 93% 이상의 의미 정확도를 유지했음을 발견했다.
휴먼랩스의 이샨크 굽타(Ishank Gupta) 공동 창업자는 "문제는 모델만이 아니라 지표이기도 하다. 영어 음운론을 위해 설계된 채점 시스템으로 비영어권 음성을 평가하고 그것을 엄밀하다고 할 수 없다. 스페인어에 대한 성능 리더보드가 베트남어에 대한 리더보드는 아니다. 단일 집계 벤치마크 점수는 지역 간 배포 결정을 지원할 수 없다"고 말했다.
이 벤치마크는 대본화되거나 인터넷에서 수집한 오디오가 아닌, 여러 지역에서 수집된 실제 두 사람 간의 대화를 기반으로 구축됐다. 각 지표는 표면적인 정확도 수치가 가리는 모델 품질의 차원을 드러내며, 이들을 종합하면 현재 글로벌 최고 순위를 차지하는 도구들이 음성 AI 도입이 가장 빠르게 성장하는 시장에 반드시 적합한 도구는 아님을 보여준다. 전체 데이터 세트는 허깅 페이스(Hugging Face)에서 이용할 수 있다.
문의처 정보: 샤르밀리 다루(Sharmilee Daru) | [email protected]
사진 - https://mma.prnasia.com/media2/2977812/Humyn_labs.jpg?p=medium600
Copyright © NEWSIS.COM, 무단 전재 및 재배포 금지